
Les fonctions, objets de première classe
Sans surprise dans un langage de programmation fonctionnel, les fonctions sont des objets de premières classes : elles se manipulent donc comme toutes les autres variables : une fonction peut prendre en entrée une fonction ou retourner une fonction. Cela permet d’ailleurs de résoudre un problème que l’on va voir sur ce billet.
Notre première fonction
Nous allons commencer par une fonction simple pour illustrer comment on déclare une fonction. Le but est de calculer une fonction 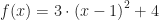
f :: (Num a) => a -> a f x = 3*(x-1)^2 + 4
On prendra toujours la peine de préciser le type de la fonction avant, comme ici. C’est le plus souvent quelque-chose qui n’est pas indispensable, mais cela est une première forme de commentaire dans son code, et, si l’on choisit bien le nom de ses variables et de ses fonctions, les commentaires peuvent très souvent être réduits.
La déclaration du type de la fonction nous dit qu’elle prend en entrée une variable d’un type numérique et renvoie en sortie une variable de ce même type. La séparation entre le type de la variable d’entrée et celle de sortie se fait par les symboles (->). La classe du type entre parenthèse et l’ensemble de symboles (=>) possède la même signification que précédemment.
La déclaration a ici la forme suivante :
- on commence par mettre le nom de la fonction,
- puis on met celle de la valeur d’entrée,
- après on place un signe égal,
- et enfin ce que doit renseigner la fonction.
On se retrouve dans un style de programmation beaucoup plus déclarative qu’en Python ou en C. On est également assez proche des notations mathématiques, les parenthèses en moins.
Une fois le script interprété, vous pouvez voir ce que la fonction vous renvoie pour 0, 1 ou -1 en écrivant dans la console :
-
f 0
-
f 1
-
f (-1)
Vous remarquez la grande différence avec le Python : aucun besoin de parenthèse ! Seul le dernier appel a besoin de parenthèse : ceci est dû à la double signification du symbole (-) : il permet à la fois de prendre l’opposé d’un nombre ou de faire une soustraction. L’interpréteur choisit plutôt de considérer toujours la soustraction, donc pour forcer le fait de considérer le nombre -1 comme un seul bloc, on utilise des parenthèses pour supprimer l’ambiguïté.
Qu’une sortie et qu’une entrée !
Tout comme en Python, une fonction ne peut renvoyer qu’une sortie. L’utilisation des n-uplets (ou tuples) permet néanmoins de faire des choses relativement transparentes à ce niveau-là, en Python comme en Haskell, mais on verra cela après.
Par contre, le fait qu’une fonction ne puisse prendre qu’une entrée parait très limitant… Mais c’est plutôt l’inverse. Dans la plupart des cas, ce n’est pas très contraignant, et seule la déclaration de la fonction sera un peu étrange, on va voir cela après. Dans les autres cas, on va même pouvoir profiter de cette particularité pour mettre en place des astuces pas piquées des hannetons. Mais ne brûlons pas les étapes.
D’abord un exemple simple d’une fonction a priori à 2 variables d’entrées : le calcul de l’Indice de Masse Corporel (ou IMC), qui est le ratio entre la masse et le carré de la taille. Pour quelques informations intéressantes sur le sujet, je vous conseille cette vidéo de Risque Alpha.
imc :: (Fractional a) => a -> a -> a imc m h = m/h^2
[Note : Il n’est pas possible de commencer le nom d’une variable ou d’une fonction par une majuscule en Haskell, d’où le choix effectué ici.]
Vous pouvez grâce à cette fonction calculer l’IMC d’un homme de 90 kg qui mesure 1m90 :
imc 90 1.90
Mais quelle est la signification de tout cela ? Il est impossible de faire une fonction de plusieurs variables ! Comment est possible ce miracle ?
Si dans la plupart des cas, on se contentera de dire que l’on vient de déclarer une fonction qui prend 2 entrées, c’est un abus de langage que la déclaration de la fonction nous permet de préciser : ce que l’on a fait, c’est créer une fonction qui prend en entrée m et renvoie une fonction dépendante de h.
On pourrait réécrire la déclaration de la fonction ainsi :
imc :: (Fractional a) => a -> (a -> a) (imc m) h = m/h^2
Je laisse cette idée faire un tour dans un coin de votre cerveau et faire un noeud dedans, ce noeud est appelé curryfication. Vous verrez que ce n’est pas le premier que vous aurez grâce (ou à cause) de Haskell. Il est tout à fait possible de curryfier des fonctions en Python, mais l’écriture ce ce type de fonction serait plus lourde qu’en Haskell et ferait intervenir des lambdas.
D’ailleurs, en parlant de lambda !
Lambda et fonction anonyme
Comme en Python, il y a la possibilité de créer des fonctions anonymes grâce à la lettre λ. Mais en Python, on sait qu’on est obligé de mettre en toute lettre lambda pour mettre en place cela (sûrement de part la difficulté de taper des lettres grecs directement grâce au clavier ?). En Haskell, on utile seulement le caractère \ qui ressemble à un λ qui aurait perdu une jambe.
Reprenons notre exemple de l’IMC, et voyons comment expliciter l’opération de curryfication :
imc :: (Fractional a) => a -> (a -> a) imc m = \h -> m/h^2
On voit bien comment on crée pour chaque valeur de m une fonction dans ces conditions. La création d’une fonction anonyme avec \ est très proche de ce qui ce fait en Python. En plus de pouvoir créer des fonctions à la volée, on verra bien des cas où les fonctions anonymes nous serrons bien utiles.
Opérateurs et fonctions
En fait, l’utilisation d’opérateur est équivalent à l’utilisation de fonction. D’ailleurs, cela peut être explicité en utilisant des parenthèses, on passe d’une utilisation classique infixe à une notation préfixe.
(/) 5 2
Cette écriture est tout à fait équivalente à
5/2
Inversement, une fonction de 2 variables peut-être plus lisible en notation infixe, c’est notamment le cas avec compare, div ou mod. Pour cela, on utilise le signe ` (alt gr 7é) autour de la fonction concernée.
5 `mod` 2
est équivalent à
mod 5 2
Filtrage par motif (pattern matching)
On souhaite définir une fonction qui renvoie le nom du chiffre donné en entrée. On peut alors simplement utiliser les gardes pour mettre en place cette fonction :
ditMonChiffre :: (Integral a) => a -> String
ditMonChiffre n
| n == 0 = "zero"
| n == 1 = "un"
| n == 2 = "deux"
| n == 3 = "trois"
| n == 4 = "quatre"
| n == 5 = "cinq"
| n == 6 = "six"
| n == 7 = "sept"
| n == 8 = "huit"
| n == 9 = "neuf"
| otherwise = "Ce n'est pas un chiffre"
Mais Haskell peut reconnaître un motif (en anglais, on parle de pattern) dans l’entrée, et on peut ainsi définir directement un comportement pour certaines entrées :
ditMonChiffre :: (Integral a) => a -> String ditMonChiffre 0 = "zero" ditMonChiffre 1 = "un" ditMonChiffre 2 = "deux" ditMonChiffre 3 = "trois" ditMonChiffre 4 = "quatre" ditMonChiffre 5 = "cinq" ditMonChiffre 6 = "six" ditMonChiffre 7 = "sept" ditMonChiffre 8 = "huit" ditMonChiffre 9 = "neuf" ditMonChiffre n = "Ce n'est pas un chiffre"
On voit les possibilités très déclaratives de ce langage comparées à des langages impératifs : on ne fait que déclarer un comportement pour différentes entrées. Attention néanmoins à l’ordre des motifs : on doit toujours aller du particulier au général, car, lors de l’exécution, lorsque le motif a été reconnu, la ligne correspondante est utilisée, et c’est fini. Par exemple, placer la dernière ligne plus tôt changerait complètement le comportement de la fonction.
Pour aller plus loin, on va définir le ou et le et logique en utilisant le filtrage par motif :
et :: Bool -> Bool -> Bool et True y = y et False _ = False ou :: Bool -> Bool -> Bool ou True _ = True ou False y = y
Lorsqu’on n’a pas besoin d’une ou de plusieurs variables d’entrée pour le calcul, on utilise le tiret du bas (underscore : _).
Cela permet aussi de définir facilement des fonctions par récurrence. Par exemple la fonction factorielle :
factorielle :: (Integral a) => a -> a factorielle 0 = 1 factorielle n = n * factorielle (n - 1)
La définition par récurrence des fonctions est centrale en programmation fonctionnelle, mais les bonnes pratiques disent souvent de les éviter. C’est un soucis central : la récursivité est très dangereuse pour la lisibilité de votre code, et la plupart des fonctionnalités souhaitées sont accessibles sans avoir besoin d’expliciter la récursivité.
La récursivité en Haskell doit être comme une bonne charpente : présente, centrale, solide, mais invisible.
La suite…
Il y aura sûrement un billet qui prendra la suite, Haskell étant parmi le langage archétypal de la programmation fonctionnel, la maitrise des fonctions est incontournable à la maitrise du langage.

 dans
dans 
 tel que :
tel que :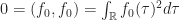
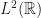 défini comme étant l’ensemble des classes d’égalité de fonctions mesurables définies presque partout sur
défini comme étant l’ensemble des classes d’égalité de fonctions mesurables définies presque partout sur 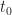 ,
, tel que :
tel que :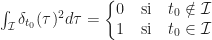
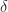 tel que :
tel que :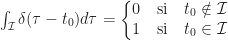

 suivant cette base, et on obtient donc :
suivant cette base, et on obtient donc :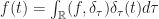

 qui, à une entrée e(t) associe une sortie s(t).
qui, à une entrée e(t) associe une sortie s(t).

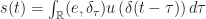
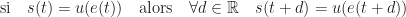
 la réponse du processus à une impulsion, alors on a :
la réponse du processus à une impulsion, alors on a :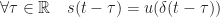
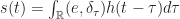



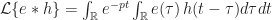
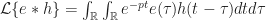
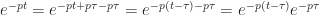

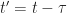 et on fait sortir les termes constants (ne dépendant pas de t’) :
et on fait sortir les termes constants (ne dépendant pas de t’) :

 , on obtient donc :
, on obtient donc :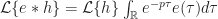
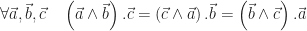
 cas à traiter. Dans l’idéal, une représentation en cube aurait été parfaite, mais cette dernière est difficilement possible sur le papier.
cas à traiter. Dans l’idéal, une représentation en cube aurait été parfaite, mais cette dernière est difficilement possible sur le papier.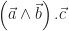
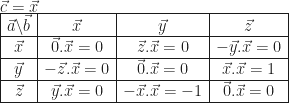


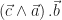 :
: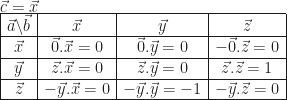


 ,
, 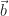 et
et  sont différents présentent un résultat non trivial : cela représente seulement
sont différents présentent un résultat non trivial : cela représente seulement 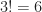 cas ;
cas ;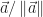 est considérée comme le premier élément de la base orthonormée considérée. On peut de la même façon considérer que la deuxième vecteur peut être représenté uniquement grâce aux deux premiers vecteurs de la base grâce au choix du deuxième vecteur de la base (voir la suite).
est considérée comme le premier élément de la base orthonormée considérée. On peut de la même façon considérer que la deuxième vecteur peut être représenté uniquement grâce aux deux premiers vecteurs de la base grâce au choix du deuxième vecteur de la base (voir la suite).

 , on travaillera dans n’importe quelle base commençant par le vecteur
, on travaillera dans n’importe quelle base commençant par le vecteur 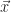 défini de la même façon.
défini de la même façon. et
et 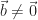 , on définit
, on définit 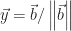 et les deux autres vecteurs de façon quelconque.
et les deux autres vecteurs de façon quelconque. et
et  :
: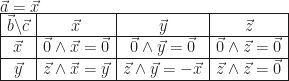
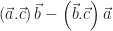 :
:
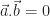
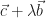 tel que :
tel que :
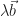 ne change rien au résultat est assez évident. L’une des manières de construire cette démonstration est de trouver un vecteur
ne change rien au résultat est assez évident. L’une des manières de construire cette démonstration est de trouver un vecteur 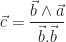

 , il suffit de prendre :
, il suffit de prendre :  par exemple, bien que dans ce cas-là, toutes les résultantes soient possibles.
par exemple, bien que dans ce cas-là, toutes les résultantes soient possibles. , une origine O et un champ équiprojectif de moment
, une origine O et un champ équiprojectif de moment 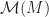 .
.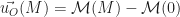 qui, à tout point de l’espace, associe la différence du moment en ce point par le moment à l’origine O.
qui, à tout point de l’espace, associe la différence du moment en ce point par le moment à l’origine O.
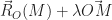 tel que :
tel que :
 tel que :
tel que :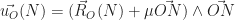
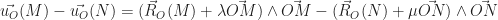
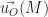 et en utilisant la propriété d’équiprojectivité du champ des moments, lorsqu’on projette cette équation sur
et en utilisant la propriété d’équiprojectivité du champ des moments, lorsqu’on projette cette équation sur  , on obtient :
, on obtient :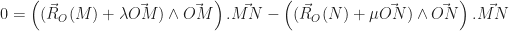
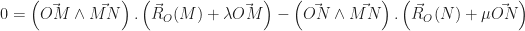


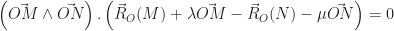

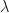 ,
,  et
et  qui correspondent respectivement à
qui correspondent respectivement à  ,
,  et
et  :
: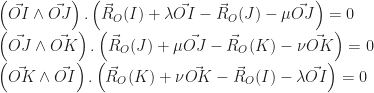


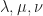 , on obtient un vecteur qui appartient aux trois familles de vecteurs en même temps :
, on obtient un vecteur qui appartient aux trois familles de vecteurs en même temps :
 tel que :
tel que :

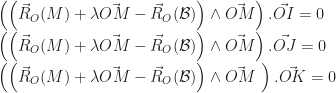
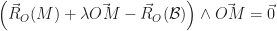
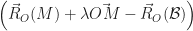 et
et 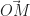 sont colinéaires. Que l’on peut réécrire par le fait qu’il existe un réel k tel que :
sont colinéaires. Que l’on peut réécrire par le fait qu’il existe un réel k tel que :
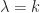 , on obtient bien que
, on obtient bien que  tel que :
tel que :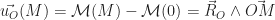


 tel que, quels que soient deux points M et N :
tel que, quels que soient deux points M et N :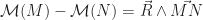
 ), définie (
), définie ( ssi
ssi  ) et positive (
) et positive ( ).
). et
et  ) qui ont la même projection. Mais la question subsiste, suivant quelle direction ? La réponse est la plus simple possible : suivant la direction créée par les deux points pris au hasard.
) qui ont la même projection. Mais la question subsiste, suivant quelle direction ? La réponse est la plus simple possible : suivant la direction créée par les deux points pris au hasard.

 est appelé résultante. Et, croyez-le ou non, ces deux formulations sont exactement équivalentes (dans un espace de dimension 3). Le fait de prouver qu’un champ vectoriel répondant à la formule de Varignon est bien équiprojectif est presque trivial : si on projette Varignon sur
est appelé résultante. Et, croyez-le ou non, ces deux formulations sont exactement équivalentes (dans un espace de dimension 3). Le fait de prouver qu’un champ vectoriel répondant à la formule de Varignon est bien équiprojectif est presque trivial : si on projette Varignon sur  , on obtient :
, on obtient :
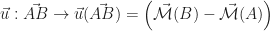 est un endomorphisme antisymétrique, que tout endomorphisme antisymétrique est forcément linéaire, qu’il se représente donc comme une multiplication par une matrice antisymétrique qui peut donc se résumer par un produit vectoriel.
est un endomorphisme antisymétrique, que tout endomorphisme antisymétrique est forcément linéaire, qu’il se représente donc comme une multiplication par une matrice antisymétrique qui peut donc se résumer par un produit vectoriel. . Elle va bien de l’espace vectoriel (des positions de point) à l’espace vectoriel (des différences de moment).
. Elle va bien de l’espace vectoriel (des positions de point) à l’espace vectoriel (des différences de moment). est dit antisymétrique s’il possède la propriété suivante :
est dit antisymétrique s’il possède la propriété suivante :
 et
et  . Voyons ce que cela nous donne :
. Voyons ce que cela nous donne :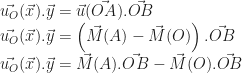
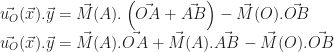
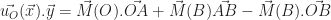

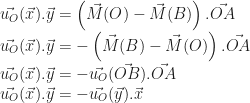
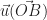 et enfin par définition des positions des points A et B.
et enfin par définition des positions des points A et B.
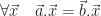
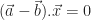
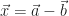 :
: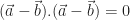

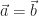



 , on en conclue par le théorème rapidement présenté en début de paragraphe que :
, on en conclue par le théorème rapidement présenté en début de paragraphe que :



 pour fêter cela !
pour fêter cela ! . On peut donc définir la matrice
. On peut donc définir la matrice  de l’endomorphisme
de l’endomorphisme  .
.

 .
. est antisymétrique (
est antisymétrique ( ).
).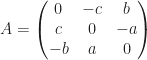
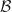 sous la forme d’une matrice colonne :
sous la forme d’une matrice colonne :


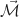 dans un espace euclidien de dimension 3 : il existe alors un unique vecteur résultant
dans un espace euclidien de dimension 3 : il existe alors un unique vecteur résultant 


 Manuscrit de thèse (en français) / PhD thesis manuscript (in French)
Manuscrit de thèse (en français) / PhD thesis manuscript (in French)







